BIOSTATISTIK
UKURAN
PEMUSATAN DATA BERKELOMPOK

DISUSUN OLEH :
KELOMPOK IV
1. ALVIANSYAH.
A
2. AYU
SEPTIANINGSIH
3. JUNAIRI
PRABOWO
4. NEOTY
OVINA
5. WINDI
PSIK A3 SEMESTER III
PROGRAM STUDI ILMU KEPERAWATAN
SEKOLAH TINGGI ILMU KESEHATAN BINA
HUSADA
PALEMBANG
2013
KATA PENGANTAR
Puji
syukur khadirat Tuhan Yang Maha Esa atas segala limpahan rahmat, inayah, taupik
dan hinayah sehingga kami dapat menyelesaikan
penyusunan makalah ini dengan sederhana tapi mungkin bermanfaat buat
yang memerlukan dan bisa di pergunakan sebagaii acuan, petunjuk, maupun pedoman
bagi pembaca.
Harapan
kami semoga makalah ini membantu dan bisa menambah pengetahuan bagi para
pembaca, sehingga kami dapat memperbaiki bentuk maupun isi makalah ini sehingga
kedepannya dapat lebih baik .
Makalah ini kami akui masih banyak
kekurangan, oleh karena itu kami harapkan kepada para pembaca utuk memberikan
masukan yang bersifat membangun untuk kesempurnaan makalah kami .
Akhir kata kami sampaikan
terimakasih kepada semua pihak yang telah berperan serta dalam penyusunan makalah
ini dari awal sampai akhir. Semoga Allah senantiasa meridhoi segala usaha kita,
amin yarobal alamin.
Palembang, Agustus
2013
Penyusun
BAB
I
PENDAHULUAN
1.1 Latar
Belakang
Proses
pengolahan data secara statistik seringkali berkaitan dengan ukuran pemusatan dan
penyebaran data. Khususnya pada tahapan statistik
deskriptif sari numerik ini dihitung untuk memberikan gambaran dari hasil
pengolahan data penelitian sebelum dilakukan proses inferensi. Pada makalah
akan diberikan beberapa pengertian ringkas dari istilah-istilah yang sering
digunakan untuk nilai-nilai statistik deskriptif yang digunakan pada pengolahan
data.
Nilai-nilai
statistik apa saja yang sering dihitung untuk memaparkan sari numerik data ini?
Data-data yang diperoleh dari hasil pengumpulan data mentah disajikan dalam
berbagai bentuk dan cara. Metode mencacah data sebagai salah satu cara paling
sederhana untuk mendapatkan informasi statistik. Cara lain penyajian data
adalah dengan membuat tabel distribusi frekuensi, baik berupa distribusi
frekuensi relatif ataupun distribusi frekuensi kumulatif. Juga dapat dilakukan
penyajian data dalam bentuk grafik, seperti grafik stem-leaf (batang -daun),
histogram, ataupun box plot.
Ukuran pemusatan
data yang sering dipakai sebagai ukuran statistik adalah mean (rata-rata), mode
(modus), median, kuartil, desil, persentil. Rata-rata adalah
jumlah dari seluruh nilai data dibagi dengan banyaknya data. Modus merupakan
nilai yang memiliki frekuensi terbesar dari suatu himpunan data. Median
adalah ukuran nilai tengah dari sejumlah nilai-nilai pengamatan yang diatur
dan disusun berdasarkan urutan data. Nilai rata-rata, modus, dan median
memiliki hubungan keterkaitan erat dari suatu distribusi frekuensi data. Ketiga
nilai ini dapat membantu menafsirkan kesimetrisan data dan kemencengan data.
Adapun ukuran
penyebaran data yang biasa dihitung adalah range (rentang), standar deviasi
(simpangan baku), kurtosis (keruncingan), skewness (kemiringan). Rentang
data menunjukkan selisih antara nilai terbesar dengan nilai terkecil dalam
suatu himpunan data. Simpangan baku adalah jumlah
mutlak selisih setiap nilai pengamatan terhadap nilai rata-rata dibagi dengan
banyaknya pengamatan. Kurtosis merupakan ukuran untuk menentukan
bentuk distribusi yang biasanya dibandingan dengan kurva distribusi normal.
Bentuk kurtosis bisa berupa leptokurtik (berpuncak tinggi dan ekor landai),
platikurtik (berpuncak rendah dan berekor pendek), dan mesokurtik (disebut juga
distribusi normal, berpuncak tidak begitu tinggi dan tidak terlalu landai). Skewness
adalah ukuran untuk menentukan kemiringan dari suatu kurva distribusi.
Penafsiran skewness dapat dilakukan secara visual, melalui koefisien
kemencengan, atau koefisien moment ketiga.
Pada makalah ini
akan dibahas ukuran pemusatan data kelompok yang akan condong membahas mean,
modus, median dan distribusi frekuensi saja.
1.2
Tujuan
Adapun tujuan
dibuatnya makalah ini adalah sebagai berikut.
1.
Untuk memahami apa itu ukuran pemusatan
data berkelompok.
2.
Untuk mamahami cara penghitungan ukuran
pemusatan data berkelompok.
3.
Untuk mengetahui rumus penghitungan
ukuran pemusatan data berkelompok.
4. Untuk
mengetahui contoh ukuruan pemusatan data berkelompok.
BAB
II
TINJAUAN
PUSTAKA
2.1 Pengertian
Ukuran Pemusatan Data Berkelompok
Ukuran pemusatan
adalah sembarang ukuran yang menunjukkan pusat segugus data, yang telah
diurutkan dari yang terkecil sampai yang terbesar atau sebaliknya dari yang
terbesar sampai yang terkecil. Salah satu kegunaan dari ukuran pemusatan data
adalah untuk membandingkan dua ( populasi ) atau contoh, karena
sangat sulit untuk membandingkan masing-masing anggota dari masing-masing
anggota populasi atau masing-masing anggota data contoh. Nilai ukuran pemusatan
ini dibuat sedemikian sehingga cukup mewakili seluruh nilai pada data yang
bersangkutan.
Ukuran pemusatan
yang paling banyak digunakan adalah nilai tengah,
median,
dan modus. Masing-masing dari ukuran pemusatan data tersebut memiliki kekurangan.
Nilai tengah akan sangat dipengaruh nilai pencilan. Median terlalu bervariasi
untuk dijadikan parameter
populasi. Sedangkan modus hanya dapat diterapkan dalam data dengan
ukuran yang besar.
2.2
Ukuran Pemusatan Data Berkelompok
Data berkelompok merupakan data yang
disajikan dalam bentuk kelas-kelas interval. Untuk menghitung ukuran pemusatan
data berkelompok, agak berbeda dari cara menghitung ukuran pemusatan data
tunggal. Untuk lebih jelasnya perhatikan uraian berikut:
Rata-rata Data Berkelompok
Untuk mencari rata-rata data
berkelompok, caranya ada tiga, yaitu cara biasa, cara rataan sementara dan cara
coding.
a. Cara Biasa
Mengapa disebut cara biasa? Karena
prinsipnya sama saja dengan menghitung nilai rataan untuk data tunggal. Rumus
yang digunakan yaitu:

Keterangan:
fi = frekuensi kelas ke i
xi = titik tengah kelas ke i
Untuk lebih jelasnya, perhatikan
contoh berikut:
Tabel di bawah ini merupakan nilai ulangan matematika
kelas XI IPA.
|
Nilai
|
Frekuensi
|
|
41 – 50
|
8
|
|
51 – 60
|
5
|
|
61 – 70
|
14
|
|
71 – 80
|
8
|
|
81 – 90
|
3
|
|
91 – 100
|
2
|
Tentukan
rata-rata dari data di atas!
Jawab:
Untuk
menghitung rata-rata data pada contoh soal di atas, terlebih dahulu kita
siapkan tabel berikut.
|
Nilai
|
Frekuensi
|
xi
|
fi.xi
|
|
41 – 50
|
8
|
45,5
|
364
|
|
51 – 60
|
5
|
55,5
|
277,5
|
|
61 – 70
|
14
|
65,5
|
917
|
|
71 – 80
|
8
|
75,5
|
604
|
|
81 – 90
|
3
|
85,5
|
256,5
|
|
91 – 100
|
2
|
95,5
|
191
|
|
Jumlah
|
40
|
2610
|
Sesudah
tabel tersebut lengkap, selanjutnya masukkan nilai-nilai yang diperlukan ke
dalam rumus di atas. sehingga rata-rata nilai dari data tersebut adalah:
b. Menghitung rata-rata data berkelompok dengan menggunakan rataan sementara
Cara ini disebut cara rataan
sementara karena terlebih dahulu menentukan nilai titik tengah yang akan diasumsikan
sebagai rataan sementara. Rumus untuk menentukan nilai rata-rata data berkelompok
dengan menggunakan rataan semetara adalah:
Keterangan:
Agar lebih
jelas, hitung nilai rataan data di atas dengan menggunakan rataan sementara.
Perhatikan tabel berikut!
|
Nilai
|
Frekuensi
|
xi
|
di
|
fi.di
|
|
41 – 50
|
8
|
45,5
|
-20
|
-160
|
|
51 – 60
|
5
|
55,5
|
-10
|
-50
|
|
61 – 70
|
14
|
65,5
|
0
|
0
|
|
71 – 80
|
8
|
75,5
|
10
|
80
|
|
81 – 90
|
3
|
85,5
|
20
|
60
|
|
91 – 100
|
2
|
95,5
|
30
|
60
|
|
Jumlah
|
40
|
-10
|
Pada tabel
di atas, titik tengah kelas interval ketiga di beri warna merah, karena
ditentukan rataan sementaranya 65,5, sehingga diberi tanda warna merah. Nah,
setelah melengkapi tabel tersebut, selajutnya tinggal menuangkan angka-angka
yang dibutuhkan ke dalam rumus rataan sementara.

Hasil
akhirnya sama dengan cara biasa. Cara mana yang harus di pilih, tergantung kita
memahaminya yang mana.
Median Data
Berkelompok
Kata median
adalah nilai tengah data. Tapi tidak cukup di tengah-tengah saja, untuk
menetukan median, datanya harus diurutkan terlebih dahulu dari yang terkecil ke
yang terbesar. Kecuali datanya sudah tersaji dalam bentuk tabel, karena biasanya
data dalam tabel sudah terurut dari yang kecil ke yang besar. Untuk data yang
tersaji dalam bentuk tabel distribusi frekuensi berkelompok, rumus mencari
mediannya sebagai berikut:
Keterangan:
Sebelum
menggunakan rumus tersebut, harus ditentukan letak median terlebih dahulu.
Median terletak di setengah dari banyak data. Setelah mengetahui letak median,
gunakan rumus di atas untuk menentukan nilai mediannya. Untuk lebih jelasnya,
akan dibahas pada contoh di bawah ini.
Untuk
memperjelas penggunaan rumus median di atas, mari lihat contoh soal di bawah
ini. Data di ambil dari soal pada pembahasan rumus rata-rata data berkelompok.
Perhatikan tabel berikut!
|
Nilai
|
Frekuensi
|
|
41 – 50
|
8
|
|
51 – 60
|
5
|
|
61 – 70
|
14
|
|
71 – 80
|
8
|
|
81 – 90
|
3
|
|
91 – 100
|
2
|
|
Jumlah
|
40
|
Tentukan median dan modus dari data
di atas!
Jawab:
Sebelum
menggunakan rumus, terlebih dahulu kita tentukan letak kelas median. Banyak
data tersebut adalah 40, sehingga median terletak pada data ke -20 yang berada
pada kelas interval ke-3. Sehingga kita mengetahui:
sehingga median dari data di atas
adalah:
Modus Data Berkelompok
Modus adalah
data yang sering muncul atau mempunyai frekuensi paling banyak. Sebuah data
bisa saja tidak mempunyai modus ketika semua data muncul dengan frekuensi yang
sama atau bahkan bisa jadi sebuah data mempunya modus lebih dari satu.
Untuk data
yang di sajikan dalam bentuk tabel distribusi frekuensi berkelompok, kita dapat
dengan mudah menentukan letak modus dengan cara melihat kelas interval yang mempunyai
frekuensi paling besar. Untuk menentukan nilainya, gunakan rumus di bawah ini!
Keterangan:
Untuk
memperjelas penggunaan modus di atas, mari lihat contoh soal di bawah ini. Data
di ambil dari soal pada pembahasan rumus rata-rata data berkelompok. Perhatikan
tabel berikut!
|
Nilai
|
Frekuensi
|
|
41 – 50
|
8
|
|
51 – 60
|
5
|
|
61 – 70
|
14
|
|
71 – 80
|
8
|
|
81 – 90
|
3
|
|
91 – 100
|
2
|
|
Jumlah
|
40
|
Tentukan median dan modus dari data
di atas!
Jawab:
Modus pada
data diatas terletak pada kelas interval ke-3 karena mempunyai frekuensi paling
besar yaitu 14. Sehingga kita mengetahui:
2.3 Rumus Ukuran Pemusatan Data
Berkelompok
Mean Data Kelompok

Median Data Kelompok

Modus Data kelompok

2.4 Contoh
Ukuran Pemusatan Data Berkelompok
Diketahui data
sebagai berikut :
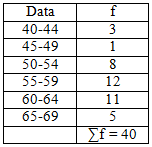
Penyelesaian :

BAB III
PENUTUP
3.1 Kesimpulan
Adapun kesimpulan dari makalah yang telah disusun ini adalah sebagai
berikut.
1. Ukuran
pemusatan adalah sembarang ukuran yang menunjukkan pusat segugus data, yang
telah diurutkan dari yang terkecil sampai yang terbesar atau sebaliknya dari
yang terbesar sampai yang terkecil.
2.
Ukuran pemusatan data yang sering
dipakai sebagai ukuran statistik adalah mean (rata-rata), mode (modus), median,
kuartil, desil, persentil. Rata-rata adalah jumlah dari seluruh
nilai data dibagi dengan banyaknya data. Modus merupakan nilai
yang memiliki frekuensi terbesar dari suatu himpunan data. Median adalah
ukuran nilai tengah dari sejumlah nilai-nilai pengamatan yang diatur dan
disusun berdasarkan urutan data. Nilai rata-rata, modus, dan median memiliki
hubungan keterkaitan erat dari suatu distribusi frekuensi data. Ketiga nilai
ini dapat membantu menafsirkan kesimetrisan data dan kemencengan data.
3. Rumus Ukuran
Pemusatan Data Berkelompok
Mean Data
Kelompok
Median Data Kelompok
Modus Data kelompok
3.2 Saran
Kami
menyarankan kepada Anda semua untuk dapat mencari lagi bahan-bahan mengenai
ukuran pemusatan data berkelompok agar dapat mengerti lebih jauh dan lebih
paham lagi.
DAFTAR
PUSTAKA
http://avstatistik.blogspot.com/2012/09/ukuran-pemusatan-dan-penyebaran-data.html
http://id.wikipedia.org/wiki/Ukuran_pemusatan_data
http://kusukamatematika.wordpress.com/2012/08/16/ukuran-pemusatan-data-berkelompok-bagian-1/
http://kusukamatematika.wordpress.com/2012/08/18/ukuran-pemusatan-data-berkelompok-bagian-2/
http://mahasuryaprabadewi.wordpress.com/2012/01/04/ukuran-pemusatan-data-berkelompok/
Wynn Resorts - Hotel and Casino - Jackson County, MS
BalasHapusContact Wynn Resorts in Jackson County, 서산 출장안마 MS at 춘천 출장샵 677-7000, or visit 여주 출장안마 us on 안성 출장안마 our website at http://www.wynnlasvegas.com. 경기도 출장안마
joya shoes 767m6guxqf939 joya sko,joya sko,joya skor,Cipő joya,zapatos joya,joya schoenen verkooppunten,Scarpe joya,chaussures joya,joya schuhe wien,joya schuhe joya shoes 550n2kyuyf739
BalasHapus